Overview
When deploying a database at GrapheneDB you get:
- Always a main node. The main node is the server hosting the database that is receiving all your write requests. You can also read from it, but ideally you do it from the Replicas to save all the resources of the main node for your writes and to be able to benefit from the redundancy and availability of the Replicas.
- Optionally Read-replicas. A Read-replica in GrapheneDB is one or more dedicated servers that maintain the same data as the main node by replicating the incoming write transactions.
Replication
Read-replicas replicate the main node write transactions and apply the operations to their data sets asynchronously. How much the replicas lag behind the main node will depend on your load, but we have designed this feature for a realistic under 100ms delay.
Replication provides redundancy and increases data availability. Replicas are deployed automatically in different Availability Zones, providing a level of fault tolerance against zonal outages.
Additionally if you add more than one Replica, replication can provide increased read capacity as clients can send read operations to different servers.
You can also add Replicas to your deployment for other purposes, such as disaster recovery, running expensive read requests without affecting your main node, etc.
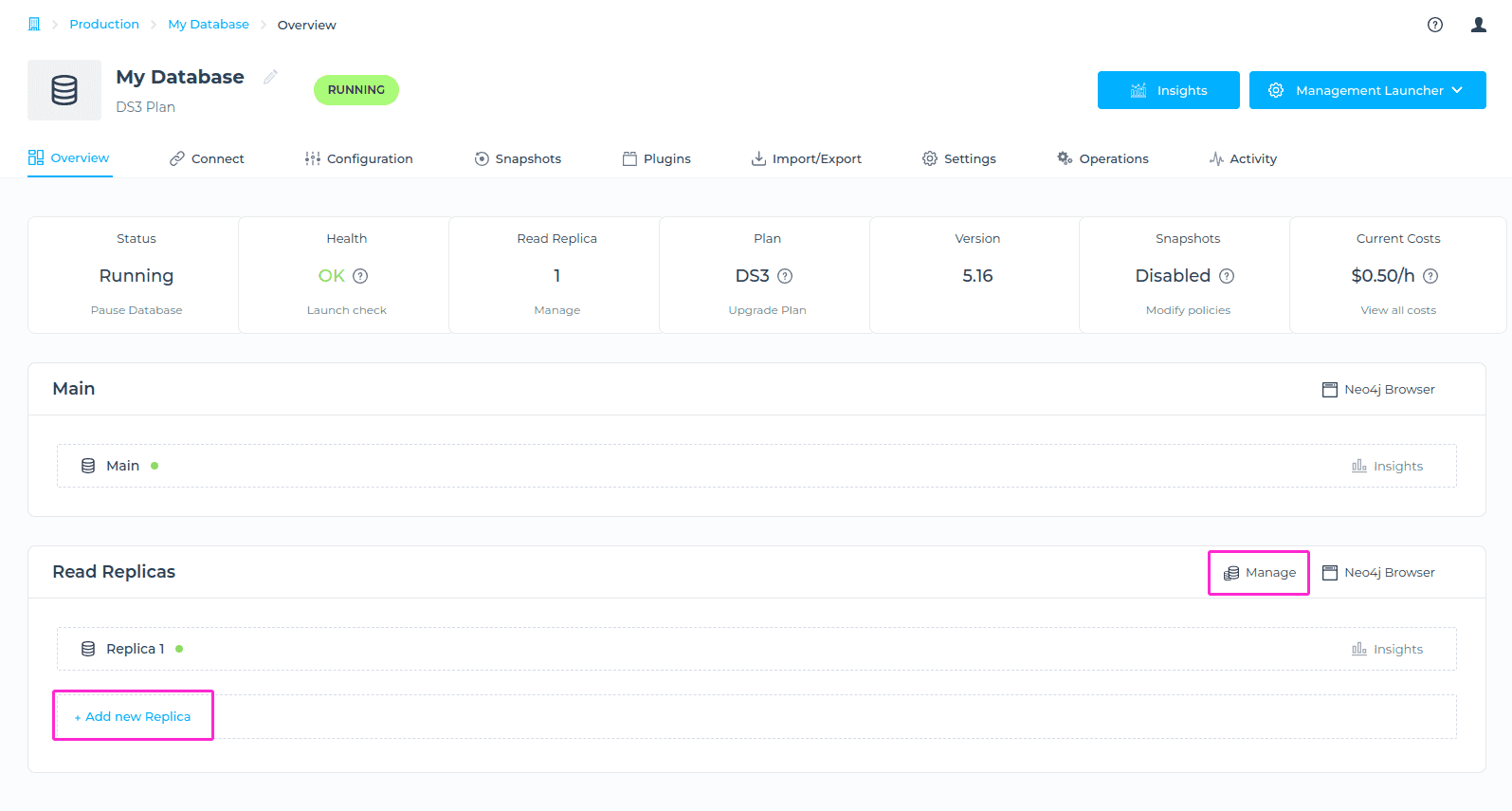
Manage Read-replicas
To add or remove a Read-replica, please navigate to the database Overview > Manage Read-replicas view.
You can select the number of Replicas that you want to be added/removed.
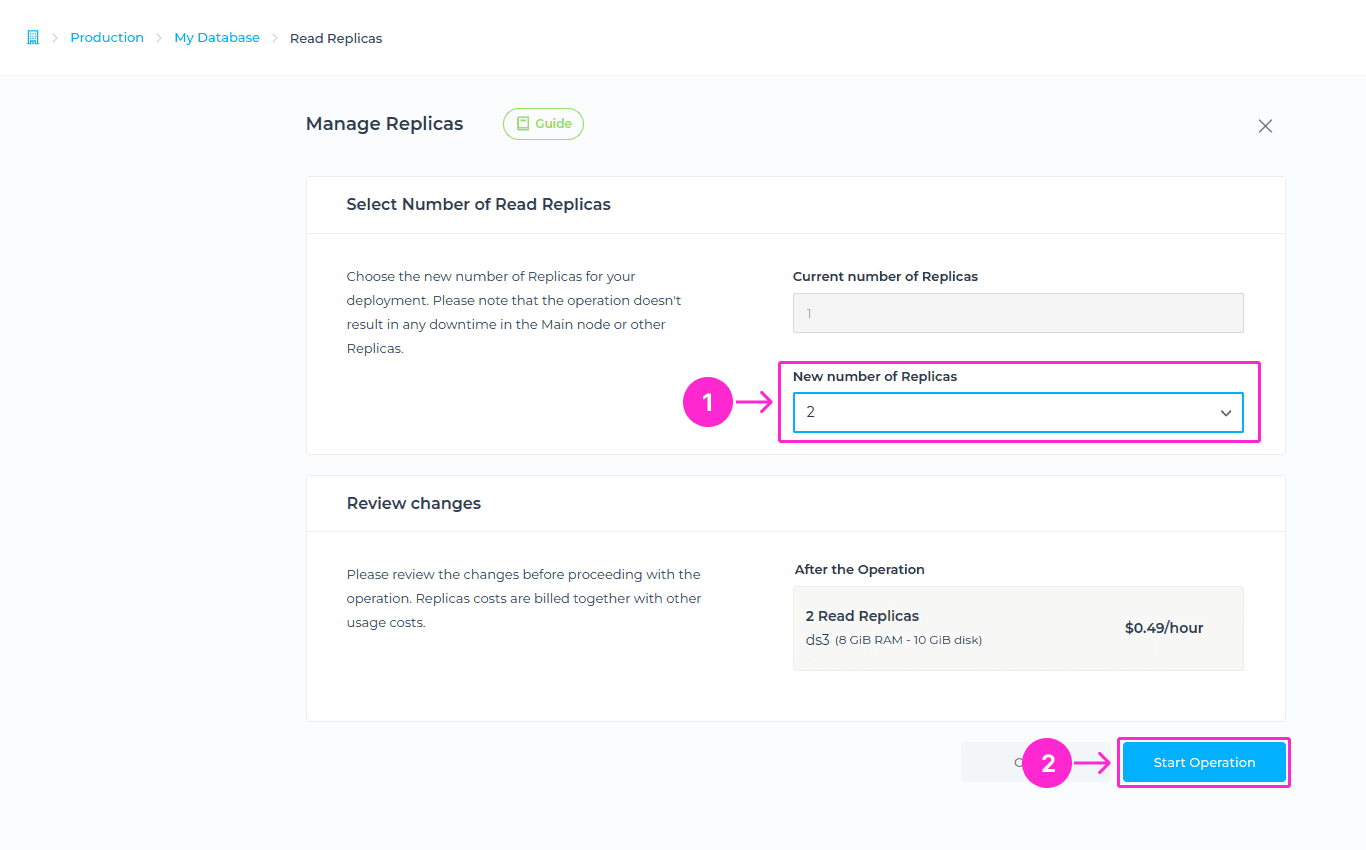
After you confirm your selection an operation will start to create/remove Replicas. When a new Replica is added it gets seeded with a snapshot of the latest data of the main node.
There is no downtime involved when adding or removing Read-replicas. Your Main node and the other Replicas are not affected by this operation.
Connection
When setting up your database connection, you can pick the connection URI in the Connect tab, depending on if you have VPC peering setup or not. More information on connection URI’s can be found here.
If you are using Bolt and a supported driver, routing of read replicas will be handled automatically by the driver.
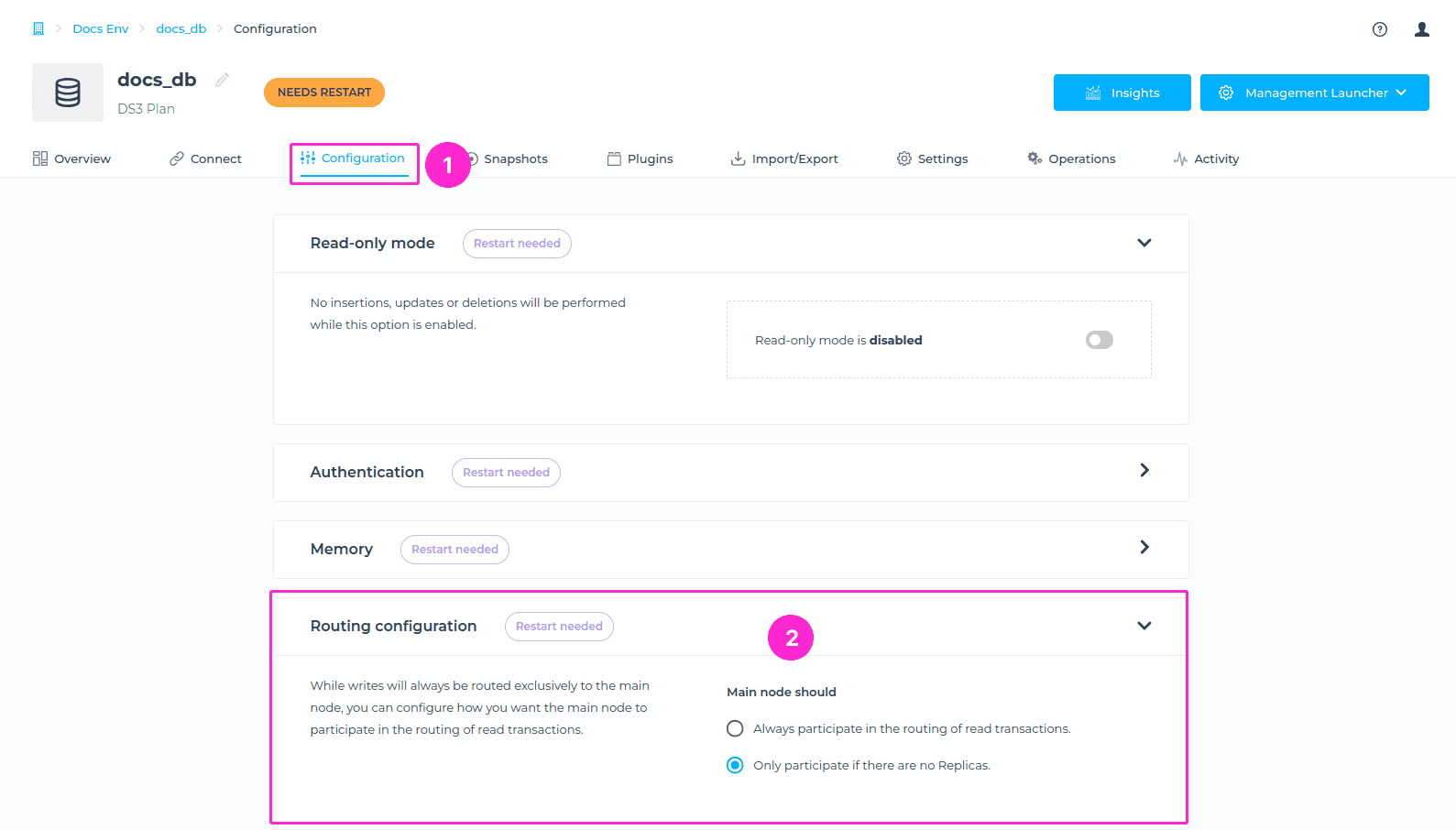
Routing Configuration
While writes will always be routed exclusively to the main node, you can configure how you want the main node to participate in the routing of read transactions. Options you have are as follows:
Main node should
- Always participate in the routing of read transactions.
- Only participate if there are no Replicas.
The choice depends on your use case and how you want to balance load and performance. Key difference is:
- Always participate ensures the main node is actively involved in read queries, distributing the workload more evenly but at the potential cost of write performance.
- Only participate if there are no replicas prioritizes the main node for write tasks, using it for reads only as a fallback when replicas are unavailable.
To locate this setting, please navigate to the Configuration tab > Routing Configuration section. There you can select option you want, and it’s required for the database to be restarted for the setting to get applied.